Оглавление
Файл robots.txt относится к текстовому типу. По нему поисковые роботы узнают, как именно необходимо сканировать сайт. Алгоритм его работы позволяет дополнительно защитить сервер, так как снижается количество запросов со стороны поисковых систем.
Иногда может возникнуть необходимость заблокировать индексацию всех или некоторых страниц. К такому решению прибегают, например, в случае использования динамических URL и других методов, которые способны привести к генерации большого числа страниц.
В этой статье мы собрали самые распространенные проблемы, возникающие при работе с robots.txt, а также описали их влияние на сайт и его положение в выдаче. Кроме того, мы перечислили и способы устранения ошибок.
Что такое файл robots.txt
Он представляет собой простейший текстовый документ. Найти файл robots.txt можно в корневом каталоге, который является верхним в иерархии. Если же разместить файл в другом каталоге, то поисковые роботы его проигнорируют. Создать robots.txt можно абсолютно в любом текстовом редакторе.
Функции robots.txt зачастую выполняют метатеги, которые можно разместить в коде конкретной страницы.
Что делает robots.txt
Данный файл обладает довольно обширным функционалом. Приведём наиболее важные цели, которые достигаются с его помощью:
- Блокировка индексации определенных страниц. При этом в поисковой выдаче они все еще могут появляться, однако текстового описания у них уже не будет;
- Блокировка медиафайлов, которая позволяет избежать попадания приватного контента в поисковую выдачу;
- Блокировка файлов ресурсов с плохими внешними скриптами. Если файл ресурсов у конкретной страницы заблокирован, поисковый робот приходит к выводу, что такой страницы не существует. Это оказывает негативное влияние на индексацию сайта в целом. При помощи robots.txt можно предотвратить полное исчезновение страницы из результатов поиска.

Опасность ошибок в файле robots.txt
Если при настройке файла robots будут допущены ошибки, определенные последствия, конечно, наступят, однако не станут фатальными. Исправив их, можно быстро восстановить полноценную работу сайта.
Поисковые роботы действуют в соответствии с различными алгоритмами, поэтому незначительные ошибки могут и вовсе не сказаться на их работе. В самом печальном случае робот проигнорирует неправильную директиву. Однако же лучше не допускать ошибок в этом файле.
Шесть главных ошибок robots.txt
Если вы заметили, что ранжирование сайта как-то странно изменилось, необходимо в первую очередь проверить файл robots. Остановимся подробно на каждой из наиболее распространённых ошибок.
Файл находится в другом каталоге

Поисковые роботы видят robots.txt только в том случае, если он располагается в корневом каталоге. Таким образом, домен и название файла в URL должны быть разделены только одним слэшем. Если между ними находится хотя бы одна дополнительная папка, поисковые роботы могут не увидеть файл. В этом случае сайт будет работать так, словно robots не существует.
Чтобы исправить ошибку, достаточно перенести файл в корневой каталог. Для этого нужен доступ к серверу. К сожалению, некоторые системы управления по умолчанию загружают robots.txt в подпапки с медиафайлами и другим аналогичным контентом. В этом случае придется найти способ обойти данную настройку.
Неправильно используется символ подстановки

*пример правильной настройки robots txt
Символом подстановки или символом-джокером называется символ, который используют для замены других. Файл robots.txt поддерживает всего два типа:
- Звездочка, которая представляет любые варианты допустимого символа;
- Значок доллара, который означает конец URL и позволяет добавлять к последней части правила. Например, файловое расширение.
Используя эти символы, необходимо проявлять умеренность, так как они способны привести к ограничениям для значительной части сайта. Если вы неправильно используете звездочку (астериск), может произойти блокировка поискового робота. Для устранения этой ошибки необходимо найти соответствующий символ, а затем переместить его или удалить.
Использование тега noindex

Чаще всего такая проблема встречается у сайтов, которые существуют уже долгие годы. В сентябре 2019 года Google перестал выполнять команду noindex в соответствующем файле. Если robots был создан до этого периода или содержит данный метатег, его страницы все равно будут индексироваться.
Для того, чтобы остановить индексацию и устранить ошибку, необходимо использовать альтернативные методы. Например, добавить метатег robots в элемент страницы head.
Закрыт доступ к скриптам и страницам стилей
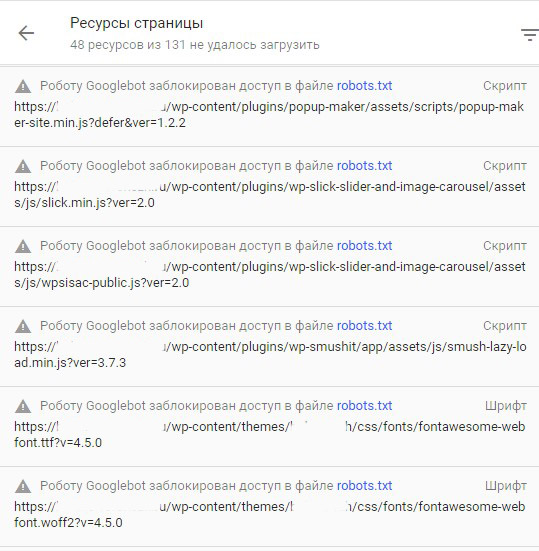
Зачастую может показаться, что решение заблокировать для поисковых роботов доступ к внутреннему коду Java и CSS является логичным. Однако доступ к таким файлам необходим поисковым системам для того, чтобы правильно сканировать страницы.
Если ресурс отображается в выдаче некорректно, имеет смысл провести проверку файла robots.txt. Если вы обнаружили запрет на доступ поискового робота к внутренним ресурсам, удалите эту строчку. Если вы нуждаетесь в блокировке определенных файлов, используйте исключение, которое позволит разрешить доступ только к нужным файлам.
Нет ссылки на карту сайта

Файл sitemap.xml позволяет поисковым роботам получить полноценную информацию о структуре сайта, а также страницах, которые необходимо считать приоритетными. Именно его поисковые роботы сканируют в первую очередь, поэтому он обязательно должен быть в файле robots.
Фактически отсутствие карты сайта нельзя назвать ошибкой, однако ее наличие существенно улучшает индексацию.
Открыт доступ к страницам, находящимся в разработке
Серьезной ошибкой является запрет доступа к страницам, которые работают, а также наличие доступа к тем страницам, которые только разрабатываются. Если сайт находится на реконструкции, имеет смысл добавить запрещающие инструкции в robots.txt, чтобы в поисковой выдаче не отразился недоработанный вариант.
После завершения работ необходимо убрать такую строчку. Об этом часто забывают, и в результате поисковые роботы не могут правильно просканировать и проиндексировать сайт.
Есть еще две ситуации, когда необходимо предпринять определенные действия:
- Сайт в разработке, но вы видите реальный трафик;
- Рабочий сайт плохо ранжируется.
В этом случае в файле robots можно прописать строчку User-Agent^*. Также можно применить строчку Disallow: /
Косая черта сделает сайт невидимым для поисковиков. Строчку можно корректировать в зависимости от эффекта, которого вы хотите добиться.
Как восстановиться после ошибок в файле
Если допущенные ошибки привели к тому, что изменилось отображение сайта в поисковой выдаче, то первое, что вы должны сделать — это предоставить поисковым роботам правильный файл robots.txt, а также удостовериться, что новые правила дают необходимый эффект. Проверить это можно при помощи специальных сервисов, таких как Screaming Frog.
После того, как вы убедитесь, что файл robots работает, как требуется, необходимо отправить запрос на проведение нового сканирования. Это можно сделать при помощи Google Search Console: необходимо добавить обновленную карту сайта и запросить новое сканирование страниц, в отношении которых были замечены нарушения.
Конкретного срока восстановления в выдаче, к сожалению, не существует. Все, что вы можете сделать — это выполнить соответствующие шаги и ждать, когда робот снова проиндексирует ваш сайт.
Профилактика robots.txt
Устранить допущенные ошибки не так сложно, как кажется, однако полезнее будет не допускать их вовсе. Файл robots.txt необходимо редактировать аккуратно и внимательно. Лучше всего привлечь для этой цели опытного специалиста. Кроме того, не лишним будет несколько раз все проверить, а также выслушать альтернативное мнение.
Прежде чем внедрять изменения на реальный сервер, имеет смысл протестировать их в так называемой песочнице. Это специально выделенная среда, в которой можно безопасно использовать любые программы.
Благодаря этому вы сможете избежать ошибок, которые часто допускаются непроизвольно. Если же худшее уже произошло, самое главное — не паниковать. Вместо этого проанализируйте возникшую проблему, оперативно внесите изменения в robots.txt и отправьте запрос на повторное сканирование. Если все было сделано вовремя, возвращение на исходные позиции произойдет в течение нескольких дней.



