Оглавление
Робот для поиска, он же поисковый краулер (от crawler, «ползать») – это бот, который используется Google, Яндекс и другими поисковыми системами для обнаружения новых страниц в сети. Основной принцип работы заключается в так называемом индексировании страниц. Краулер поисковой системы постоянно сканирует все попадающиеся страницы, находит на них ссылки и переходит по этим ссылкам. Вся собранная информация заносится им в специальную базу данных, индекс. В дальнейшем индекс используется для различия уже встречавшихся и новых страниц, а также для проверки обновления их содержимого.
Отметим, что краулер может называться множеством синонимов. В русскоязычном сегменте сети популярны термины «поисковый робот», «поисковый бот», «поисковый паук». В англоязычном интернете используются «webrobot», «webspider» и «ant».
Как видит поисковый робот
С точки зрения краулера любой сайт выглядит совсем не так, как с точки зрения пользователя. Визуальный контент игнорируется, интерес представляет техническая информация.
Следующие параметры являются при анализе приоритетными:
- текущий веб-сервер;
- IP-адрес;
- наличие постоянного http-соединения (keep-alive);
- текущая дата в GMT-формате;
- URL сайта и/или страницы;
- ответ http-заголовка страницы;
- код перенаправления;
- тип и объем контента;
- правила cookie, действующие на сайте;
- внешние и внутренние ссылки страницы.
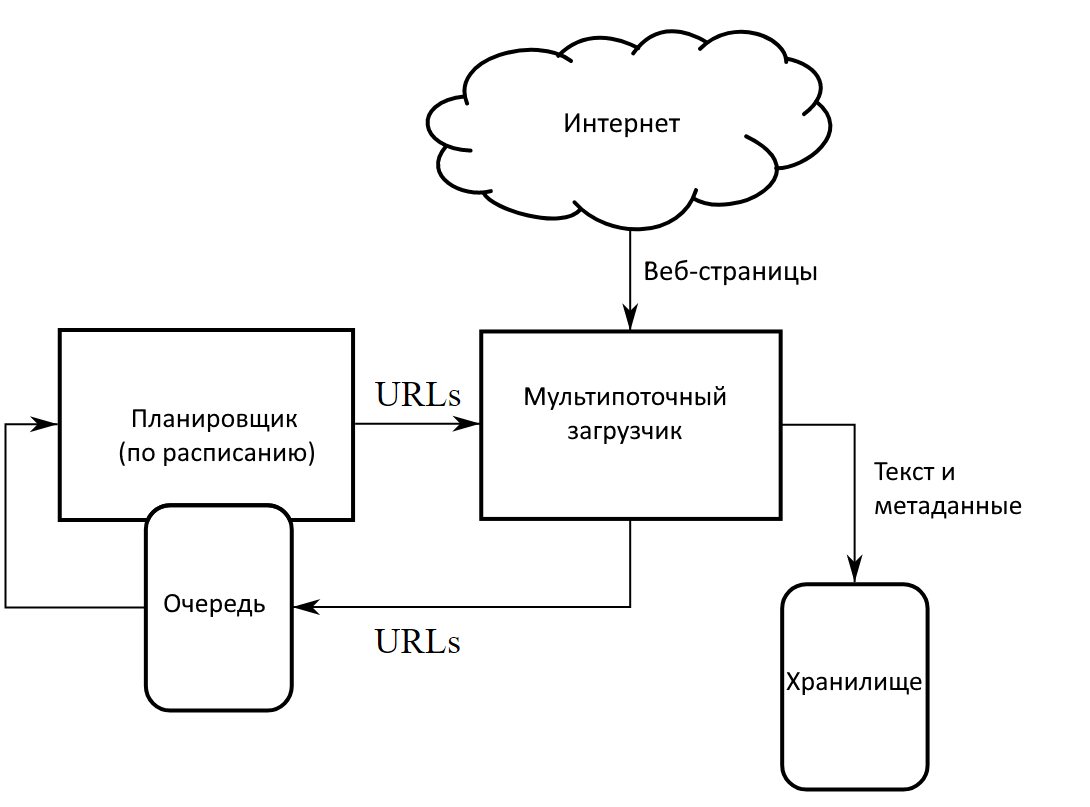
Как работают поисковые роботы
Рассмотрим принципы работы краулеров на примере образцов Google и Яндекса. Обобщенная цепочка действий выглядит так:
- переход по URL на страницу;
- сканирование контента;
- сохранение содержимого на сервере (обычно с конвертацией данных в удобный для поисковика формат);
- переход по новому URL и повторение действий.
Детали регламентируются конкретной поисковой системой и паттернами правил для определенного типа ботов. Например, порядок сканирования может разливаться по максимальному количеству переходов внутри одного сайта, количеству посещений, разрешению или запрету зацикливания и т.д. Поведение типичного краулера Google, например, выглядит следующим образом:
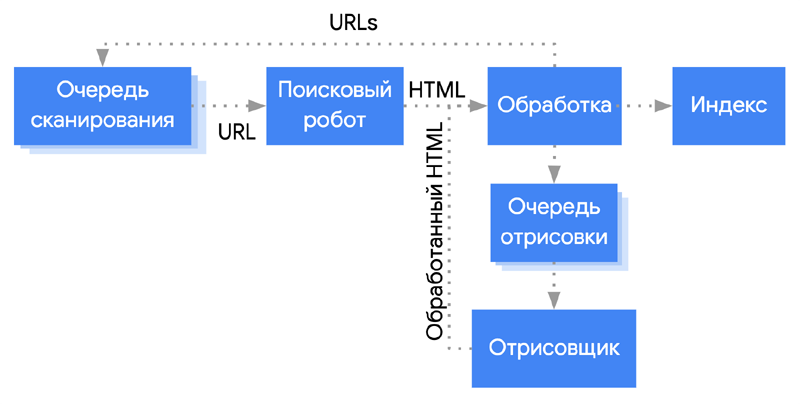
Информация по просканированным страницам попадает от краулеров в базы данных не сразу. Яндекс обновляет индекс в срок от нескольких дней до двух недель, Google – несколько раз в сутки.
Типы поисковых роботов
Для оптимизации процесса при сканировании разного контента поисковики используют разные типы краулеров.
Например, Google разделяет ботов для обработки общего качества страницы, качества рекламы, сканирования изображений, сканирования видео, а также для новостного контента и мобильных страниц. Все эти типы ботов обладают отдельным user agent и для любого из них можно создать директивное обращение в стандарте исключения (об этом немного ниже).
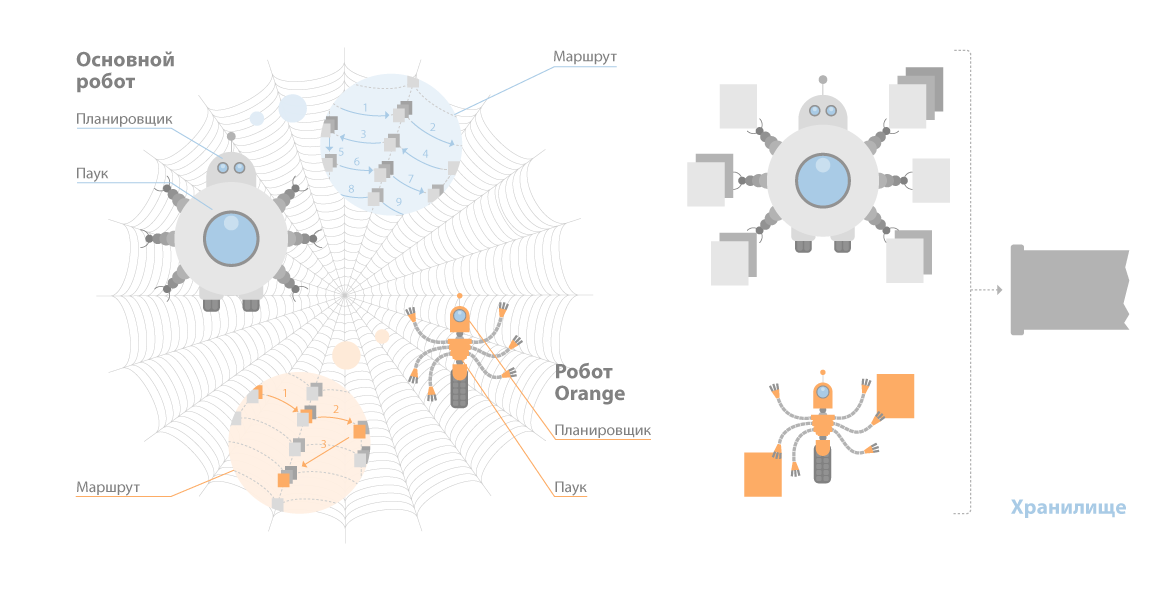
Что касается Яндекса, то основных краулеров у него всего два: стандартный и быстрый Orange. Последовательность операций стандартного бота:
- планировщик выстраивает очередность сканирования данных;
- робот получает от планировщика маршрут;
- робот обходит документы по этому маршруту;
- если от сайта есть корректный ответ, идет скачивание данных;
- идентифицируется ряд параметров документа, включая язык;
- сведения отправляются в кэш Яндекса.
Почему сайт не индексируется целиком
Владельцы сайтов могут заметить, что когда ресурс введен в пользование, он индексируется не только не сразу, но еще и не целиком – когда до нового сайта добираются поисковые боты, они могут индексировать сначала только несколько страниц. Это связано с тем, что каждый конкретный краулер имеет лимит по количеству обращений к конкретному сайту (так называемый краулинговый бюджет). Этот лимит может быть суточным или месячным, но суть не меняется. При помощи Google Search Console можно увидеть общее количество запросов сканирования сайта; для этого нужно перейти на вкладку «Статистика сканирования».
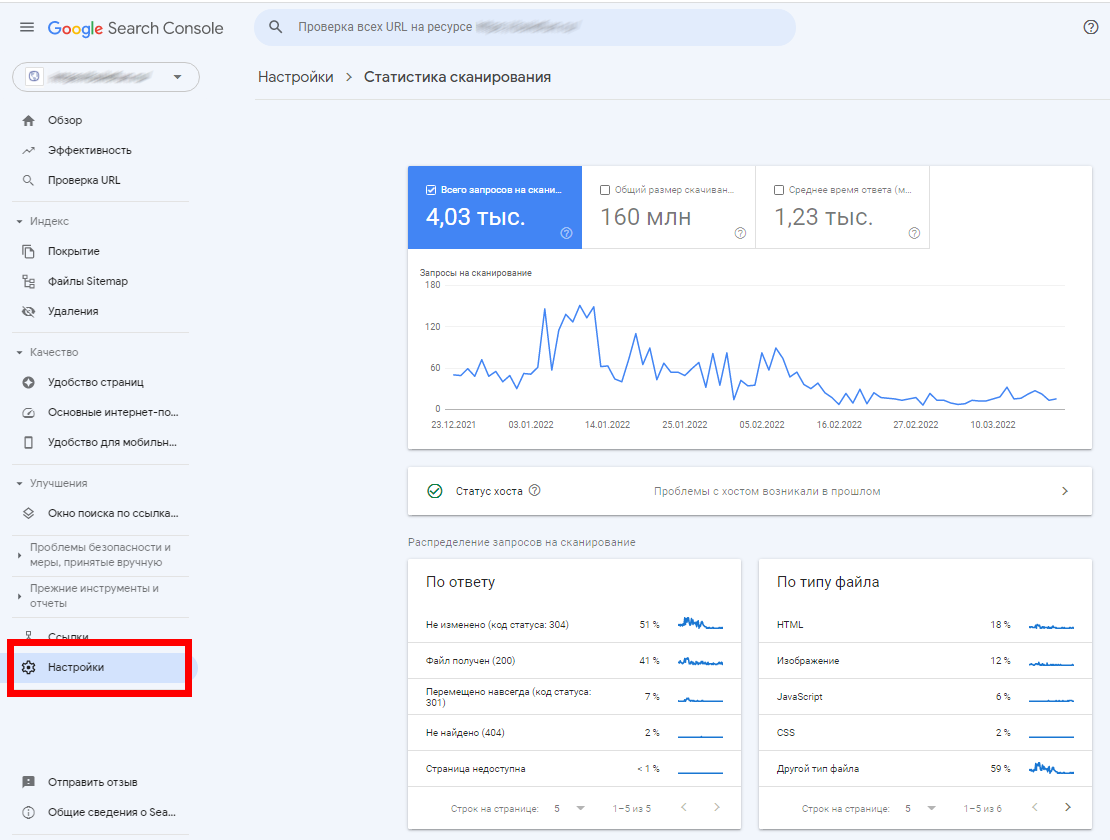
Кроме того, надо помнить и про дополнительные факторы: бот вполне может повторно сканировать одну и ту же страницу (что тоже снижает его лимит по количеству обращений), а также может иметь ограничение сканирования – например, по уровню глубины доступа или по размеру текстового контента. По этим причинам сайт, особенно крупный и имеющий сложную структуру, для полного индексирования требует нескольких подходов сканирования.
Краулеры в виде пользователей
Роботы поисковых систем всегда играют по правилам: они никогда не делают вид, что являются пользовательским клиентом. Однако для отдельных сервисов полностью соблюдать все ограничения для ботов может быть фатально: с учетом затрат на бюджеты обращений и интервалы между обращениями, сканирование может быть очень медленным, особенно для сервисов, которым нужно обрабатывать огромные массивы данных. В таких случаях разработчики конкретных сервисов создают личных ботов, которые представляются пользовательским клиентом, браузером. Они точно так же индексируют страницы, но отображаются в статистике ресурса как пользователи.
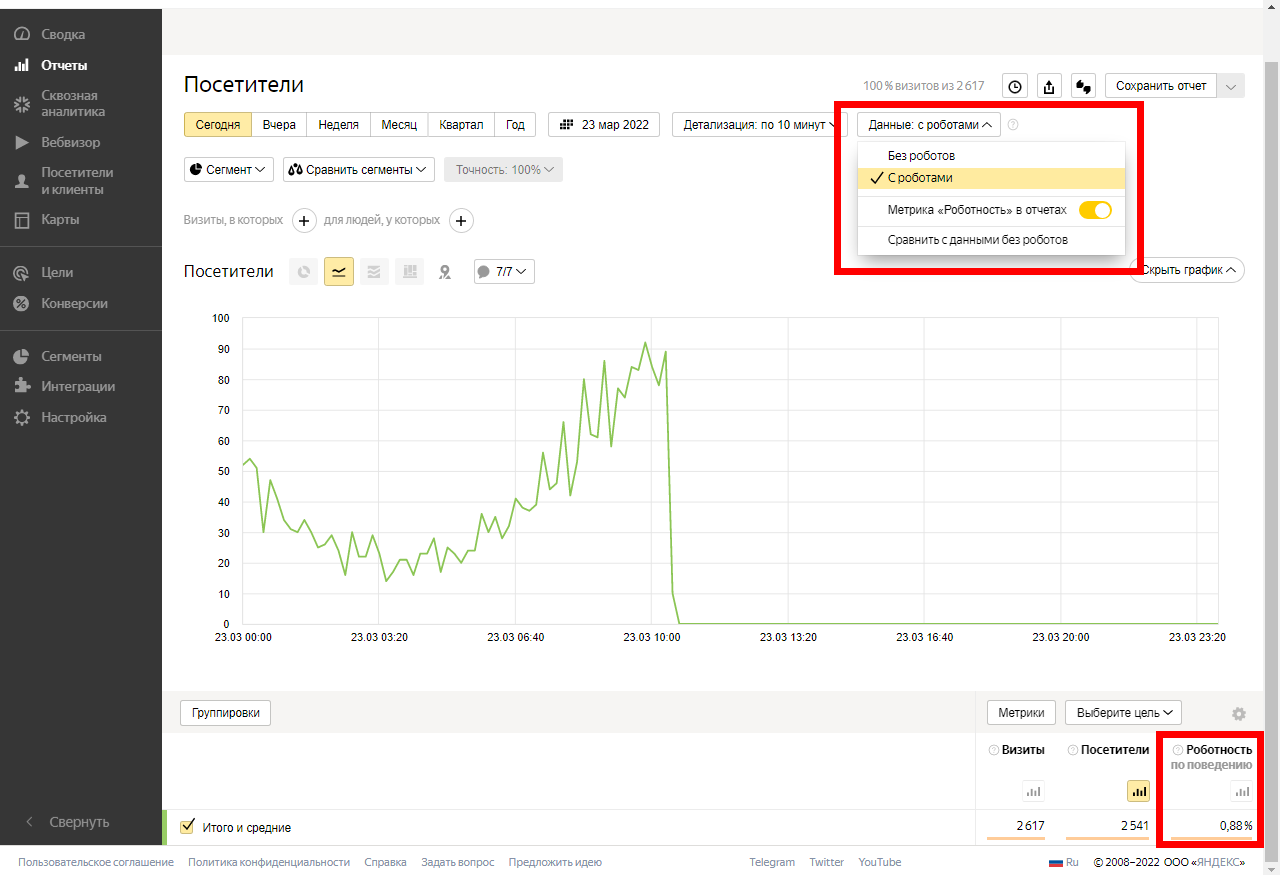
Чтобы боты, в том числе притворяющиеся пользователями, не искажали статистику посещений, придуманы алгоритмы по их отсеву. Например, Яндекс.Метрика может ограничить отображение данных по пользователям, которые соответствуют параметру «роботность по поведению» — если по поведенческим факторам это краулер, значит, его в общую статистику можно не включать. Для отсева надо открыть любой отчет, выбрать строку «данные с роботами» и использовать наиболее подходящий фильтр.
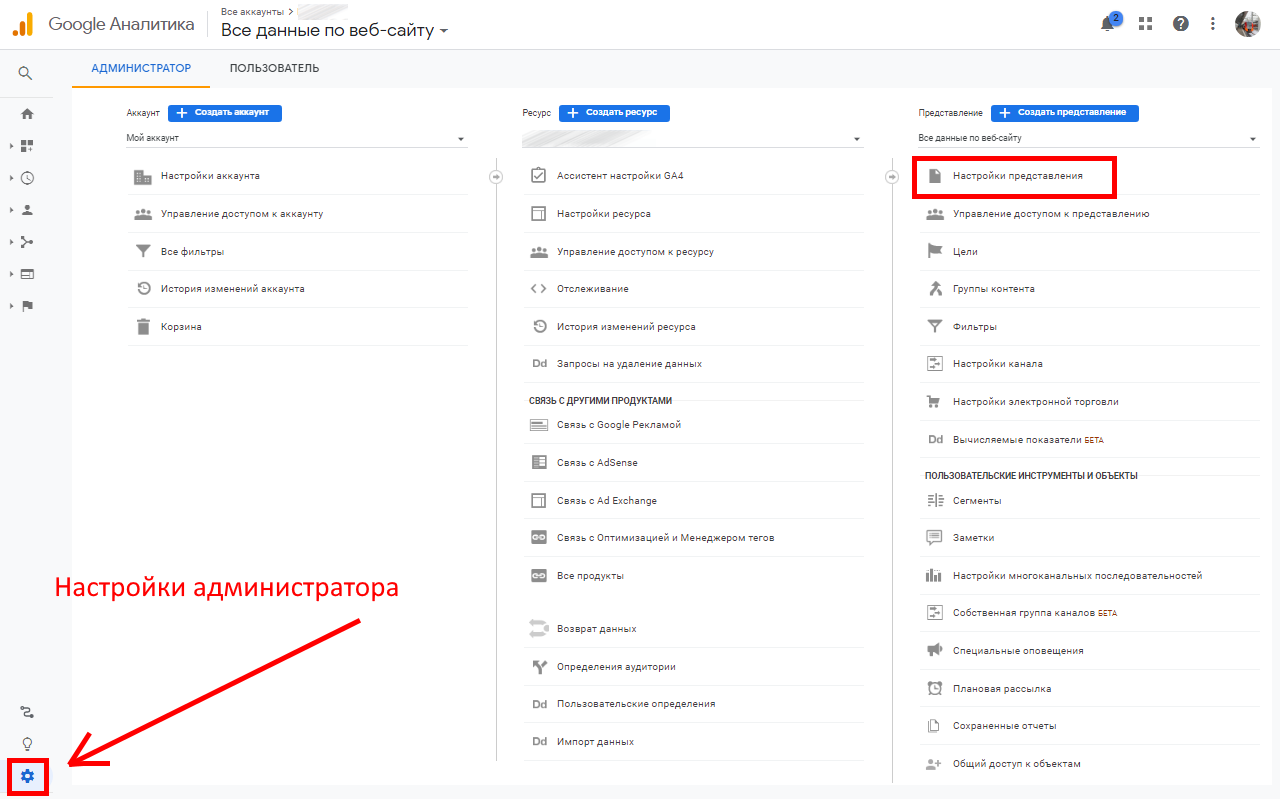
Фильтрация есть и в Google Analytics. В настройках администратора и параметрах представления можно отметить чекбокс «исключить обращение роботов и пауков», и их активность не будет отмечаться в отчетах GA.
Полезные и вредные
Проблемы краулеров для владельца сайта не только в медленной индексации или искажении статистики посещений. Возможно и возникновение других неприятностей.
Например, роботы генерируют объем трафика. Казалось бы, для передачи информации в индекс нужен ничтожный объем данных, однако надо помнить – краулеры используются не только в Яндексе и Google. Во-первых, они применяются многими другими поисковиками, которые не пользуются популярностью и малоизвестны, но тем не менее существуют. Во-вторых, краулеры создаются для различных аналитических сервисов, SEO-инструментов, статистических сайтов –можно вспомнить хотя бы известнейший Amazon. При ограниченных ресурсах сервера множество поисковых ботов могут стать полноценной проблемой. Есть и откровенно вредные боты, которые добывают данные для дальнейшего использования – например, для слива электронных адресов в базы данных и последующих рекламных рассылок.
Для борьбы с вредной стороной поисковых ботов используют различные средства. Например, многие CMS имеют различные плагины и расширения, ограничивающие воздействие краулеров на сайт. В WordPress, к примеру, популярностью пользуется Blackhole for Bad Bots. Он добавляет триггерную скрытую ссылку в колонтитул страниц и запрещает краулерам переходить по ней (с помощью команды в robots.txt). Если краулер игнорирует правило – значит, это вредоносный робот и он попадет в ловушку.
Запрет на сканирование
Основной инструмент для ограничения сканирования вашего сайта – это директивы в robots.txt. В этот файл можно прописывать временные интервалы, которые бот должен соблюдать при обращении к странице, и конкретные разделы, которые нельзя сканировать. Это позволяет снизить нагрузку на сервер.
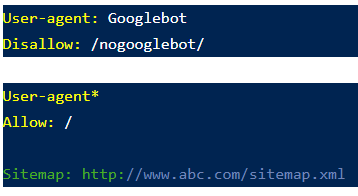
Директивы могут настраиваться по-разному. Например, директива со скриншота ниже расшифровывается так:
- карта сайта опубликована на странице http://www.abc.com/sitemap.xml;
- для краулеров Google запрещен обход ссылок, начинающихся с http://abc.com/nogooglebot/;
- краулеры других систем и сервисов могут сканировать сайт без ограничений.
По умолчанию любой сайт доступен всем ботам, если только в robots.txt не указано обратное. Однако надо помнить, что эти указания носят рекомендательный характер. То, что делает поисковый робот, контролируется исключительно его собственными директивами. При этом соблюдение рекомендаций из robots.txt считается хорошим тоном, а если они не соблюдаются – этот бот, скорее всего, создан с неблаговидными целями.
В заключение дадим несколько простых директив, пользующихся наибольшей популярностью.
- Директива для запрета на индексацию сайта для всех ботов
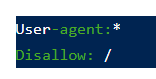
- Директива для запрета индексирования конкретной страницы
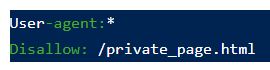
- Директива для запрета на индексацию страницы конкретному боту, с указанием user agent
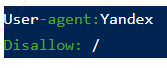
- Директива для ограничения индексирования каталога со всем содержимым
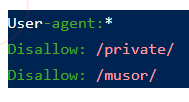
Еще раз подчеркнем, что директивы в robots.txt это рекомендации, а не полноценные команды. Для полной блокировки страниц или всего сайта от поисковиков проще всего поставить пароль или прописать соответствующую команду в http-заголовок.



