Оглавление
Об удивительном рядом
Последнее время, благодаря ребятам, с которыми я работаю в Arcticlab, меня заинтересовал язык и вообще человеческая речь. Со времен школы не любил русский и вообще эту тему, но как теперь оказалось, я просто смотрел на нее не под тем углом. В русском языке, на котором говорит трехлетний ребенок. больше математики, чем во всем курсе средней школы. Когда мы пишем или говорим на нем, наш мозг производит множество сложных вычислений, о которых мы даже не задумываемся.
В одной из последних книг на эту тему, которую я еще до конца не прочитал, была высказана замечательная мысль, что для ученого, изучающего человеческий язык, фундаментальным фактом о нем является то, что такая сложная система вообще не должна существовать. Ошеломляет мысль о том, что большинство объектов во вселенной не разговаривают, не обмениваются и никак не интерпретируют информацию. А мы, в свою очередь, благодаря языку можем объяснить такие вещи, как смена дня и ночи или уж совсем абстрактные понятия, например, транзитивность.
О чем это я
Теперь по существу. По большей части в этом посте я буду писать о письменной речи. Оказывается (для многих, наверно, все нижеприведенные факты элементарны, но для меня это открытия), есть некоторый набор правил, благодаря которым можно проанализировать текст и сделать из этого анализа кучу выводов.
Конечно, первое что может прийти в голову, это посчитать слова. То есть мы можем посчитать, сколько в тексте всего слов, какое среднее количество слов используется в предложении, как часто слово употребляется в тексте, как часто слова употребляются в связке с другим словом. И посчитав хотя бы часть из этого, мы можем делать выводы о рассматриваемом тексте. В SEO все, конечно, привыкли, что основная метрика текстов — это ключевые слова, — их количество, плотность. Эту ситуацию надо менять, ведь поисковые алгоритмы все время совершенствуются, и есть несколько простых принципов, по которым некачественные seo’шные тексты можно отсекать.
Например, самыми часто употребляемыми словами являются служебные слова, то есть союзы, частицы, предлоги и местоимения. И вот если все слова из рассматриваемого текста расположить в порядке частоты их использования, от самого часто используемого к самому редкому, и пронумеровать их по порядку, то среди первых слов в этом списке будут как раз служебные слова, но если текст, который мы анализируем, — seo’шный, то среди этих служебных слов будут неестественно присутствовать и обычные существительные…точнее, не обычные, а ключевые слова, по которым пытаются продвинуть страницу с данным текстом.
О чудесном законе Ципфа
Также по словам можно проверить закон Ципфа. Этот закон — “отвал башки”, особенно если вы оцениваете текст на его естественность (если просто, то естесnвенным языком называется язык, используемый людьми для общения с людьми). Эта эмпирическая закономерность имеет следующий смысл: если все слова из рассматриваемого текста расположить опять же в порядке частоты их использования, от самого часто используемого к самому редкому, и пронумеровать их по порядку, то второе по частотности слово будет встречаться в тексте примерно в два раза реже, чем первое, а третье в три раза реже, чем первое и т.д. Объясняется же эта закономерность корреляционными свойствами аддитивных цепей Маркова (это из Математической статистики, см. wikipedia). Кстати, благодаря закону Ципфа можно не только определять. является ли текст естественным, но и есть ли смысл в какой-либо тарабарщине типа Рукопись Войнича (опять же, см. wikipedia). Как наглядный пример закона Ципфа — график частности слов в романе «Моби Дик».
Про кластеры — связки слов
Теперь усложним задачу и рассмотрим не одно слово, а несколько, то есть кластер. Если взять слова, связанные по смыслу, и проанализировать эти связки… Да, стоит остановиться на том, как можно определить, что слова связаны по смыслу. Если в какой-то части текста обсуждается какая-то тема, то слова, связанные с этой темой в этой части текста будут употребляться чаще, чем в других частях, и семантически будут связанны между собой. Для определения этих связок — кластеров нам необходимо определить размер анализируемых участков текста (не путать с частями текста, о которых шла речь в предыдущем предложении ), таких участков, на которые мы разобьем текст и в которых хотим найти связки слов. Как вариант, это может быть одно — два предложения. Потом анализируем получившиеся кластеры на неоднородность распределения по тексту, то есть те связки, которые будут распределены неравномерно, и будут кластерами, связанными со смыслом рассматриваемых частей текста. И, конечно, если весь текст посвящен какой-либо теме, то эту тему мы сможем вычислить по кластерам, которые равномерно встречаются по всему тексту. Например, проанализировав таким образом сегодняшнюю статью — «Here It Comes … The $375,000 Lab-Grown Beef Burger» на сайте журнала Science, мы выделили кластер:
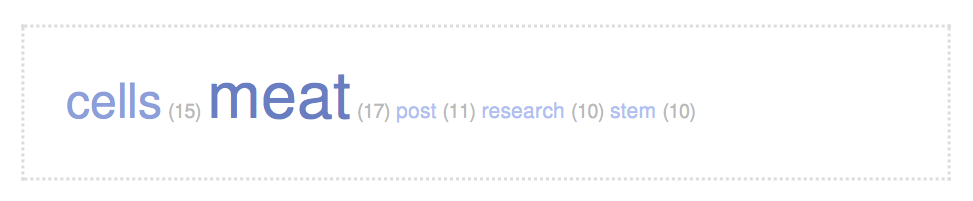
и из полученного кластера вполне можно сделать вывод о теме статьи.
Дальше полученную информацию можно использовать, например, для того, чтобы определить, подходит ли посадочная страница для какого-либо запроса. Есть еще несколько применений такого анализа, но об этом и других интересных фактах анализа текста я расскажу в своем следующем посте.


